大数据又一次引领技术变革大潮,智者会审时度势力、寻觅良机。
作为中国官方扶持的战略性新兴产业,大数据产业已逐步从概念走向落地“大数据”和“虚拟化”两大热门领域得到了广泛关注和重视,90%企业都在用大数据,相对应的人才需求量大幅度增加。
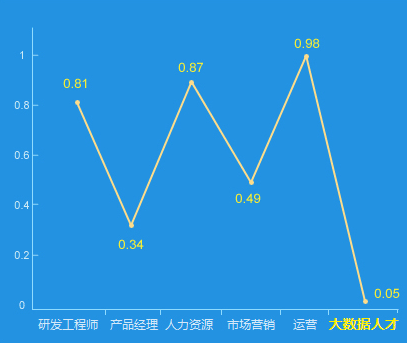
人才供给指数
人才缺口大(100个大数据岗位,5个人才供应)
学了大数据,薪酬年年涨,拦都拦不住!
你是否已经意识这是你人生中的一个重要转机?能不能抓住这个时代的机遇,就在于你对大数据信息的应用和获取。而如何成为大数据时代的弄潮儿,掌握当下紧缺的软件技能是关键!谷歌、阿里巴巴、百度、京东都在急需掌握大数据技术的人才!无论你精通大数据的哪一项类,都将在未来职场脱颖而出!
(万元)
36-50万
30-35万
26-29万
21-25万
10-20万
10万

技术目标:能搭建大数据应用平台、开发分析应用程序。熟悉工具或算法、编程、包装、优化或者部署不同的MapReduce事务。以大数据技术为核心,研发各种基于大数据技术的应用程序及行业解决方案。
| 阶段S1 — 基础 | |
|---|---|
| 课程1、使用JAVA实现面向对象过程 | |
| 1)第1章-初识Java | |
| 2)第2章-数据类型和运算符 | |
| 3)第3章-流程控制 | |
| 4)第4章-数组 | |
| 5)第5章-综合练习【动物乐园】 | |
| 6)第6章-类和对象 | |
| 7)第7章-继承和多态 | |
| 8)第8章-抽象类和接口 | |
| 9)第9章-异常 | |
| 10)第10章-综合练习【迷你DVD管理器】 | |
| 课程2、使用JAVA实用技术 | |
| 1)第1章-集合框架和泛型 | |
| 2)第2章-实用类 | |
| 3)第3章-输入输出和反射 | |
| 4)第4章-注解和多线程 | |
| 5)第5章-网络编程技术 | |
| 6)第6章-XML技术 | |
| 7)第7章-综合练习【电影院售票系统】 | |
| 8)第8章-项目案例【超市收银系统】 | |
| 课程3、Linux基础 | |
| 1)Linux系统概述1)Linux系统概述 | |
| 2)系统安装及相关配置 | |
| 3)Linux网络基础 | |
| 4)OpenSSH实现网络安全连接 | |
| 5)vi文本编辑器 | |
| 6)用户和用户组管理 | |
| 7)磁盘管理 | |
| 8)Linux文件和目录管理 | |
| 9)Linux终端常用命令 | |
| 10)linux系统监测与维护 | |
| 课程4、大数据开发核心技术程 | |
| 1)大数据应用发展、前景 | |
| 2)Hadoop 2.x概述及生态系统 | |
| 3)Hadoop 2.x环境搭建与测试 | |
| 4)HDFS文件系统的架构、功能、设计 | |
| 5)HDFS Java API使用 | |
| 6)YARN 架构、集群管理、应用监控 | |
| 7)MapReduce编程模型、Shuffle过程、编程调优 | |
| 8)分布式部署Hadoop 2.x | |
| 9)分布式协作服务框架Zookeeper | |
| 10)HDFS HA架构、配置、测试 | |
| 11)HDFS 2.x中特性 | |
| 12)YARN HA架构、配置 | |
| 13)实战应用 | |
| 第二阶段S2 — 核心 | |
|---|---|
| 课程1、Hive | |
| 1)Hive功能、体系结构、使用场景 | |
| 2)Hive环境搭建、初级使用 | |
| 3)Hive原数据配置、常见交互方式 | |
| 4)Hive中的内部表、外部表、分区表 | |
| 5)Hive 数据迁移 | |
| 6)Hive常见查询(select、where、distinct、join、group by) | |
| 7)Hive 内置函数和UDF编程 | |
| 8)Hive数据的存储和压缩 | |
| 9)Hive常见优化(数据倾斜、压缩等) | |
| 10)结合【用户浏览日志】实际案例分析 | |
| 11)依据业务设计表 | |
| 12)数据清洗、导入(ETL) | |
| 13)使用HiveQL,统计常见的网站指标 | |
| 课程2、大数据协作框架 - Sqoop Flume Oozie | |
| 1)Sqoop功能、使用原则 | |
| 2)将RDBMS数据导入Hive表中(全量、增量) | |
| 3)将HDFS上文件导出到RDBMS表中 | |
| 4)Flume 设计架构、原理(三大组件) | |
| 5)Flume初步使用,实时采集数据 | |
| 6)如何使用Flume监控文件夹数据,实时采集录入HDFS中 | |
| 7)任务调度框架Oozie | |
| 8)使用Oozie调度MapReduce Job和HiveQL | |
| 9)定时调度任务使用 | |
| 课程3、大数据Web开发框架 - 大数据WEB 工具Hue | |
| 1)Hue架构、功能、编译 | |
| 2)Hue集成HDFS | |
| 3)Hue集成MapReduce | |
| 4)Hue集成Hive、DataBase | |
| 5)Hue集成Oozie | |
| 课程4、分布式数据库 - HBase | |
| 1)HBase是什么、发展、与RDBMS相比优势、企业使用 | |
| 2)HBase Schema、表的设计 | |
| 3)HBase 环境搭建、shell初步使用(CRUD等) | |
| 4)HBase 数据存储模型 | |
| 5)HBase Java API使用(CRUD、SCAN等) | |
| 6)HBase 架构深入剖析 | |
| 7)HBase 与MapReduce集成、数据导入导出 | |
| 8)如何设计表、表的预分区(依据具体业务分析讲解) | |
| 9)HBase 表的常见属性设置(结合企业实际) | |
| 10)HBase Admin操作(Java API、常见命令) | |
| 11)【用户浏览日志】进行分析 | |
| 12)依据需求设计表、创建表、预分区 | |
| 13)进行业务查询分析 | |
| 14)对于密集型读和密集型写进行HBase参数调优 | |
| 课程5、Storm实时数据处理 | |
| 1)Storm简介和课程介绍 | |
| 2)Storm原理和概念详解 | |
| 3)Zookeeper集群搭建及基本使用 | |
| 4)Storm集群搭建及测试 | |
| 5)API简介和入门案例开发 | |
| 6)Spout的Tail特性、storm-starter及maven使用、Grouping策略 | |
| 7)实例讲解Grouping策略及并发 | |
| 8)并发度详解、案例开发(高并发运用) | |
| 9)案例开发—计算网站PV,通过2种方式实现汇总型计算。 | |
| 10)案例优化引入Zookeeper锁控制线程操作 | |
| 11)计算网站UV(去重计算模式 | |
| 12)【运维】集群统一启动和停止shell脚本开发 | |
| 13)Storm事务工作原理深入讲解 | |
| 14)Storm事务API及案例分析 | |
| 15)Storm事务案例实战之 ITransactionalSpout | |
| 16)Storm事务案例升级之按天计算 | |
| 17)Storm分区事务案例实战 | |
| 18)Storm不透明分区事务案例实战 | |
| 19)DRPC精解和案例分析 | |
| 20)Storm Trident 入门 | |
| 21)Trident API和概念 | |
| 22)Storm Trident实战之计算网站PV | |
| 23)ITridentSpout、FirstN(取Top N)实现、流合并和Join | |
| 24)Storm Trident之函数、流聚合及核心概念State | |
| 25)Storm Trident综合实战一(基于HBase的State) | |
| 26)Storm Trident综合实战二 | |
| 27)Storm Trident综合实战三 | |
| 28)Storm集群和作业监控告警开发 | |
| 第三阶段S3 — 提升 | |
|---|---|
| 课程1、Scala语言 | |
| 1)Scala编程详解:基础语法 | |
| 2)Scala编程详解:条件控制与循环 | |
| 3)Scala编程详解:函数入门 | |
| 4)Scala编程详解:函数入门之默认参数和带名参数 | |
| 5)Scala编程详解:函数入门之变长参数 | |
| 6)Scala编程详解:函数入门之过程、lazy值和异常 | |
| 7)Scala编程详解:数组操作之Array、ArrayBuffer以及遍历数组 | |
| 8)Scala编程详解:数组操作之数组转换 | |
| 9)Scala编程详解:Map与Tuple | |
| 10)Scala编程详解:面向对象编程之类 | |
| 11)Scala编程详解:面向对象编程之对象 | |
| 12)Scala编程详解:面向对象编程之继承 | |
| 13)Scala编程详解:面向对象编程之Trait | |
| 14)Scala编程详解:函数式编程 | |
| 15)Scala编程详解:函数式编程之集合操作 | |
| 16)Scala编程详解:模式匹配 | |
| 17)Scala编程详解:类型参数 | |
| 18)Scala编程详解:隐式转换与隐式参数 | |
| 19)Scala编程详解:Actor入门 | |
| 课程2、Spark | |
| 1)Spark 初识入门 | |
| 2)Spark 概述、生态系统、与MapReduce比较 | |
| 3)Spark 编译、安装部署(Standalone Mode)及测试 | |
| 4)Spark应用提交工具(spark-submit,spark-shell) | |
| 5)Scala基本知识讲解(变量,类,高阶函数) | |
| 6)Spark 核心RDD | |
| 7)RDD特性、常见操作、缓存策略 | |
| 8)RDD Dependency、Stage常、源码分析 | |
| 9)Spark 核心组件概述 | |
| 10)案例分析 | |
| 11)Spark 高阶应用 | |
| 12)Spark on YARN运行原理、运行模式及测试 | |
| 13)Spark HistoryServer历史应用监控 | |
| 14)Spark Streaming流式计算 | |
| 15)Spark Streaming 原理、DStream设计 | |
| 16)Spark Streaming 常见input、out | |
| 17)Spark Streaming 与Kafka集成 | |
| 18)使用Spark对【用户浏览日志】进行分析 | |
| 课程3、企业大数据平台应用 | |
| 1)企业大数据平台概述 | |
| 2)大数据平台基本组件 | |
| 3)集群环境的准备(系统、基本配置、规划等) | |
| 4)搭建企业大数据平台 | |
| 5)以实际企业项目需求为依据,搭建平台 | |
| 6)需求分析(主要业务) | |
| 7)框架选择(Hive\HBase\Spark等) | |
| 8)真实服务器手把手环境部署 | |
| 9)安装Cloudera Manager 5.3.x | |
| 10)使用CM 5.3.x安装CDH 5.3.x | |
| 11)如何使用CM 5.3.x管理CDH 5.3.x集群 | |
| 12)基本配置,优化 | |
| 13)基本性能测试 | |
| 14)各个组件如何使用 | |
| 课程4、大数据高薪面试剖析 | |
| 1)大数据项目 | |
| 2)企业大数据项目的类型 | |
| 3)技术架构(如何使用各框架处理数据) | |
| 4)冲刺高薪面试 | |
| 5)面试简历编写(把握要点) | |
| 6)面试中的技巧 | |
| 7)常见面试题讲解 | |
| 8)如何快速融入企业进行工作(对于大数据公司来说非常关键) | |
| 9)学员答疑 | |
| 10)针对普遍问题进行公共解答 | |
| 11)一对一的交流 | |




只要功夫深,小白秒变大神,你想要的,北大青鸟给您!
学历不是硬伤,
爱拼的人生没有学不会的!
你的薪资,
从来与学历无关
课程非常系统、全面,
实践反推理论。
0基础,怕什么,
你还有老师啊
手里没钱很纠结
担心被骗很犹豫
没关系
我们可以先就业再付钱!
入学签订就业协议
企业来校招聘
还有专业老师推荐就业
全方位就业服务